Chapter 13: Penalised and Bayesian Regression for Small Samples
Learning Objectives
By the end of this chapter, you will be able to explain why ordinary maximum likelihood can fail with sparse regression data, recognise separation in logistic regression, use penalised estimates to stabilise small-sample models, describe how weakly informative Bayesian priors regularise estimates, and report sensitivity checks without presenting regularisation as a substitute for information.
The Problem of Sparse Data in Regression
Classical maximum likelihood estimation can become unstable when sample sizes are small, events are rare, or predictors nearly separate outcome groups. In logistic regression, separation occurs when a predictor or predictor combination nearly or perfectly predicts the binary outcome. The fitted probabilities then approach 0 or 1, coefficient estimates become very large, and Wald standard errors stop being useful. A practical diagnostic is to inspect simple predictor-by-outcome tables for zero cells and to check whether the logistic model warns that fitted probabilities are numerically 0 or 1.
Penalised regression and Bayesian regression respond to the same problem in different language. Penalised regression adds a constraint to the likelihood so that extreme coefficients are pulled back toward more stable values. Bayesian regression combines the likelihood with prior distributions. Weakly informative priors serve as regularisation when the data alone are too thin to support precise estimates. Neither approach creates information that is not in the data. Both make the modelling assumptions more explicit.
Choosing Among Regularisation Strategies
Regularisation covers a family of strategies, and the appropriate choice depends on the outcome, the modelling goal, and the specific source of instability.
| Problem in the small dataset | Better starting point | Why |
|---|---|---|
| Sparse binary outcome or separation warnings in logistic regression | Firth logistic regression | Produces finite bias-reduced estimates when ordinary maximum likelihood breaks down |
| Continuous outcome with correlated predictors | Ridge regression | Shrinks all slopes and reduces instability from collinearity without selecting a single “winner” |
| Continuous outcome with many candidate predictors and a screening goal | LASSO | Can set weak or unstable coefficients to zero, but selection should be treated as exploratory |
| Strong prior knowledge or a need to express assumptions directly | Bayesian regression with weakly informative priors | Regularises estimates through explicit prior distributions and requires convergence checks |
| Main goal is explanation of one pre-specified effect | Simpler pre-specified model plus sensitivity analysis | Penalised selection can obscure the estimand if the target effect was already known |
| Main goal is prediction | Penalised model with transparent tuning and validation | Prediction requires checking out-of-sample behaviour, not only coefficient significance |
For small samples, the safest workflow is to fit the simplest scientifically meaningful model first, then use regularised estimates as sensitivity checks or as explicitly labelled prediction tools. If regularisation changes the substantive conclusion, report that instability rather than hiding it behind a single preferred model.
Firth-Penalised Logistic Regression
Firth’s method reduces small-sample bias in likelihood estimation and is especially useful for sparse binary outcomes or separation (Firth 1993; Heinze and Schemper 2002). Table 13.1 shows the structure of a small project-success example. Most low-planning projects fail and most high-planning projects succeed, which creates a separation risk.
Table 13.1
Sparse project-success data used for the logistic-regression example
| Planning band | No success | Success | Success rate |
|---|---|---|---|
| Planning score 1-5 | 11 | 1 | 8% |
| Planning score 6-9 | 0 | 8 | 100% |
Note. The outcome is nearly separated by planning score. This is the setting where ordinary logistic regression can produce unstable estimates.
The ordinary logistic model fits in R, but the fitted probabilities are close to 0 or 1. That is a warning sign even if the software returns coefficients. Table 13.2 compares ordinary maximum-likelihood estimates with Firth-penalised estimates when the logistf package is available.
Table 13.2
Standard and Firth-penalised logistic-regression estimates
| Method | Term | Estimate | Std. error | p-value |
|---|---|---|---|---|
| Standard ML | Planning score | 43.85 | 42168.42 | 0.999 |
| Standard ML | Prior experience | 44.72 | 57464.52 | 0.999 |
| Firth | Planning score | 1.02 | 0.80 | 0.218 |
| Firth | Prior experience | 1.66 | 1.54 | 0.328 |
Note. The standard-model standard errors are Wald estimates from glm(); under separation they can become extremely large or effectively unbounded, especially when R warns that fitted probabilities are numerically 0 or 1. In this example, fitted probabilities close to 0 or 1 occurred: yes. Use logistf or another penalised method immediately when that warning appears. Firth's method adds a penalty proportional to the log determinant of the Fisher information matrix, reducing small-sample bias and preventing infinite estimates under separation. Coefficients remain on the log-odds scale and can be exponentiated for odds-ratio interpretation.
Interpretation should focus on direction, uncertainty, and model fragility. A finite Firth coefficient is a more stable estimate under a penalised likelihood, not confirmation that the effect size is precisely known. In small samples, report the event counts, variables in the model, penalisation method, confidence intervals, and whether ordinary logistic regression showed separation warnings.
Ridge Regression as Shrinkage
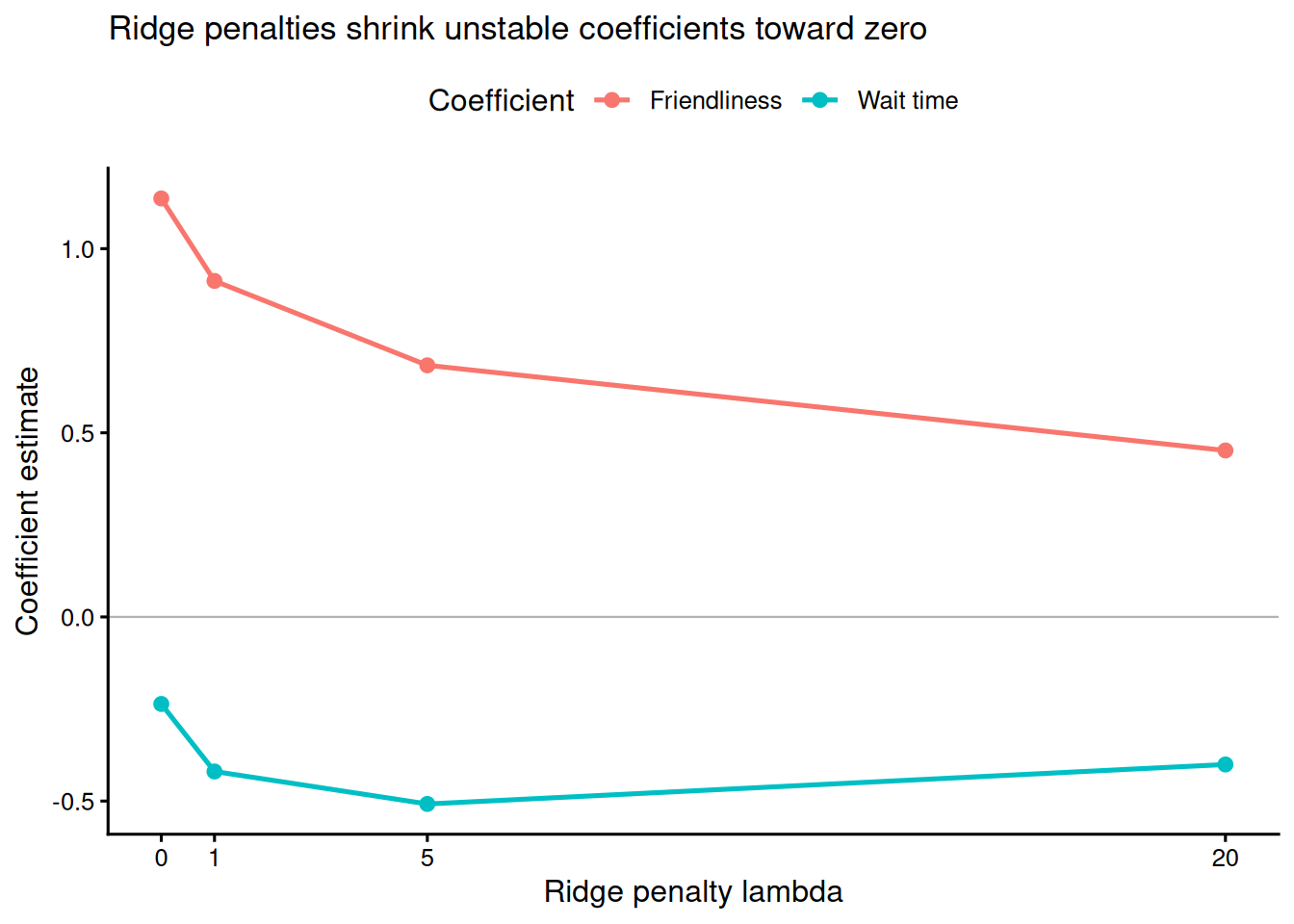
Ridge regression shrinks regression coefficients toward zero by adding a penalty proportional to the squared coefficient size. It is useful when predictors are correlated, sample size is modest, or the goal is prediction rather than unpenalised coefficient interpretation (Harrell 2015). Table 13.3 and Figure 13.1 show the same small customer-satisfaction regression under increasing ridge penalties.
Table 13.3
Ridge coefficient estimates under increasing penalty strength
| Lambda | Intercept | Wait time | Friendliness |
|---|---|---|---|
| 0 | 5.94 | -0.24 | 1.14 |
| 1 | 5.94 | -0.42 | 0.91 |
| 5 | 5.94 | -0.51 | 0.68 |
| 20 | 5.94 | -0.40 | 0.45 |
Note. Predictors were standardised to mean = 0 and SD = 1 before fitting because the L2 penalty is scale-dependent. Lambda = 0 is the ordinary least-squares solution. Coefficients apply to standardised predictors unless back-transformed.
As lambda increases, the slope estimates move toward zero. That shrinkage can reduce overfitting and improve prediction, but it also changes the estimand: the coefficients are penalised estimates, not ordinary least-squares coefficients. Report the penalty-selection method, whether predictors were standardised, and whether the model was used for prediction or interpretation.
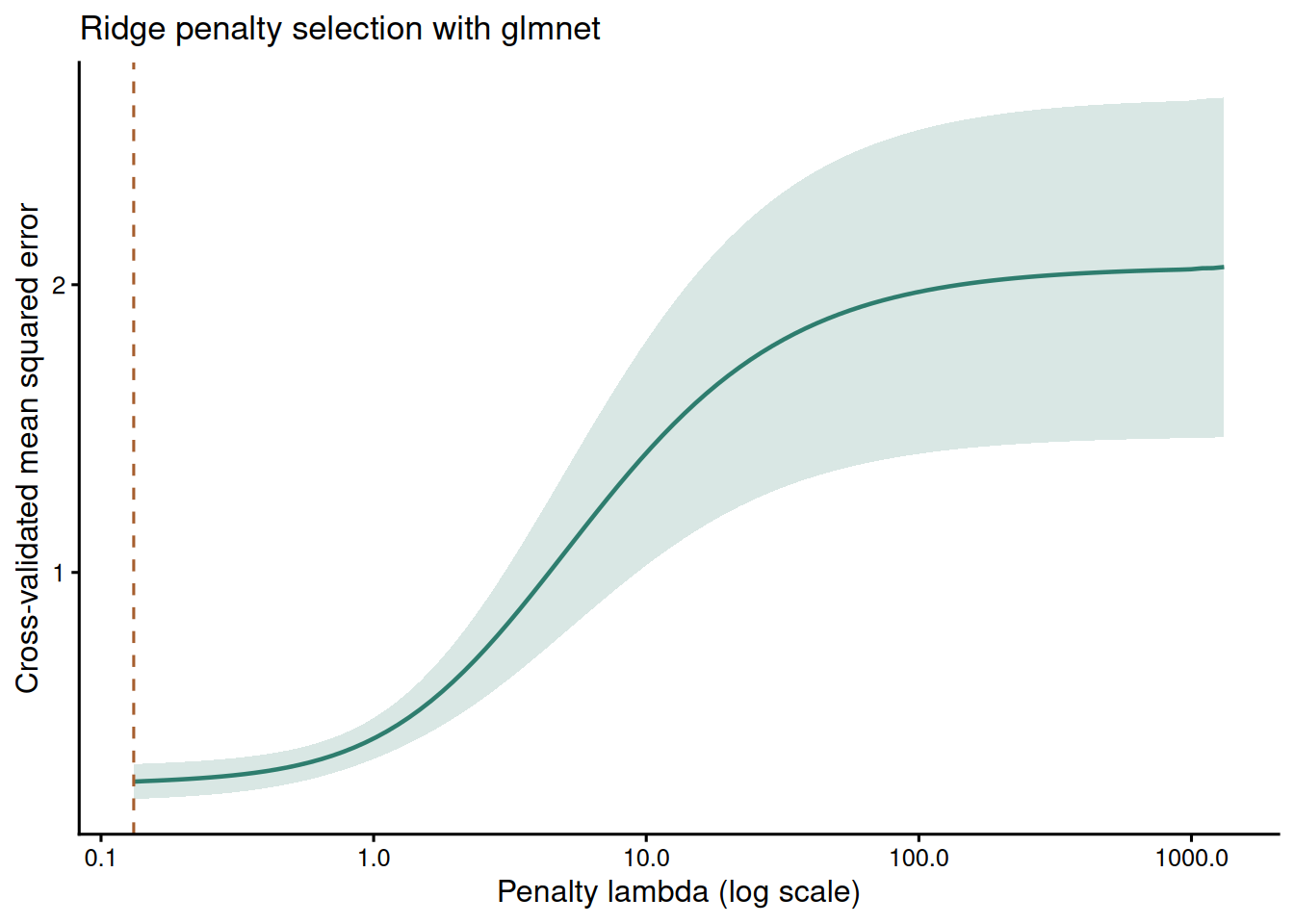
Choosing the Ridge Penalty with glmnet
The code below shows the same ridge idea using glmnet, which is the package readers are most likely to use in practice. The predictors are standardised internally, alpha = 0 requests ridge rather than lasso, and cross-validation selects a penalty. The sample is deliberately small, so the cross-validation curve should be read as a tuning aid rather than as a precise estimate of out-of-sample performance.
Table 13.4
Ridge estimates from glmnet at the selected penalty
| Term | Estimate |
|---|---|
| (Intercept) | 2.183 |
| wait_time | -0.180 |
| friendliness | 0.740 |
Note. The selected lambda is the value minimising cross-validated prediction error. In small samples, repeat the analysis under plausible modelling choices rather than treating one cross-validation split as definitive.
LASSO for Predictor Screening
The LASSO uses an L1 penalty rather than the squared L2 penalty used by ridge regression. This means that, as the penalty increases, some coefficients can be shrunk exactly to zero. That property makes LASSO useful for cautious predictor screening when a small dataset contains more candidate predictors than the sample can estimate reliably. It should not be treated as proof that excluded variables are irrelevant. With small samples, selected predictors can change under modest resampling or under a different set of candidate variables.
The example below uses 30 observations and five candidate predictors. Cross-validation chooses two common penalty values: lambda.min, which minimises the cross-validated error, and lambda.1se, which chooses a more parsimonious model within one standard error of that minimum.
Table 13.5
LASSO coefficients under two cross-validated penalty choices
| Term | lambda.min | lambda.1se |
|---|---|---|
| Intercept | 60.21 | 60.30 |
| Service quality | 3.10 | 2.27 |
| Response speed | -1.61 | -1.08 |
| Price fairness | -0.81 | 0.00 |
| Staff training | 1.14 | 0.06 |
| Waiting-room comfort | -0.19 | 0.00 |
Note. Coefficients were estimated with standardised predictors. Values equal to 0 indicate variables removed by the LASSO penalty at that tuning value.
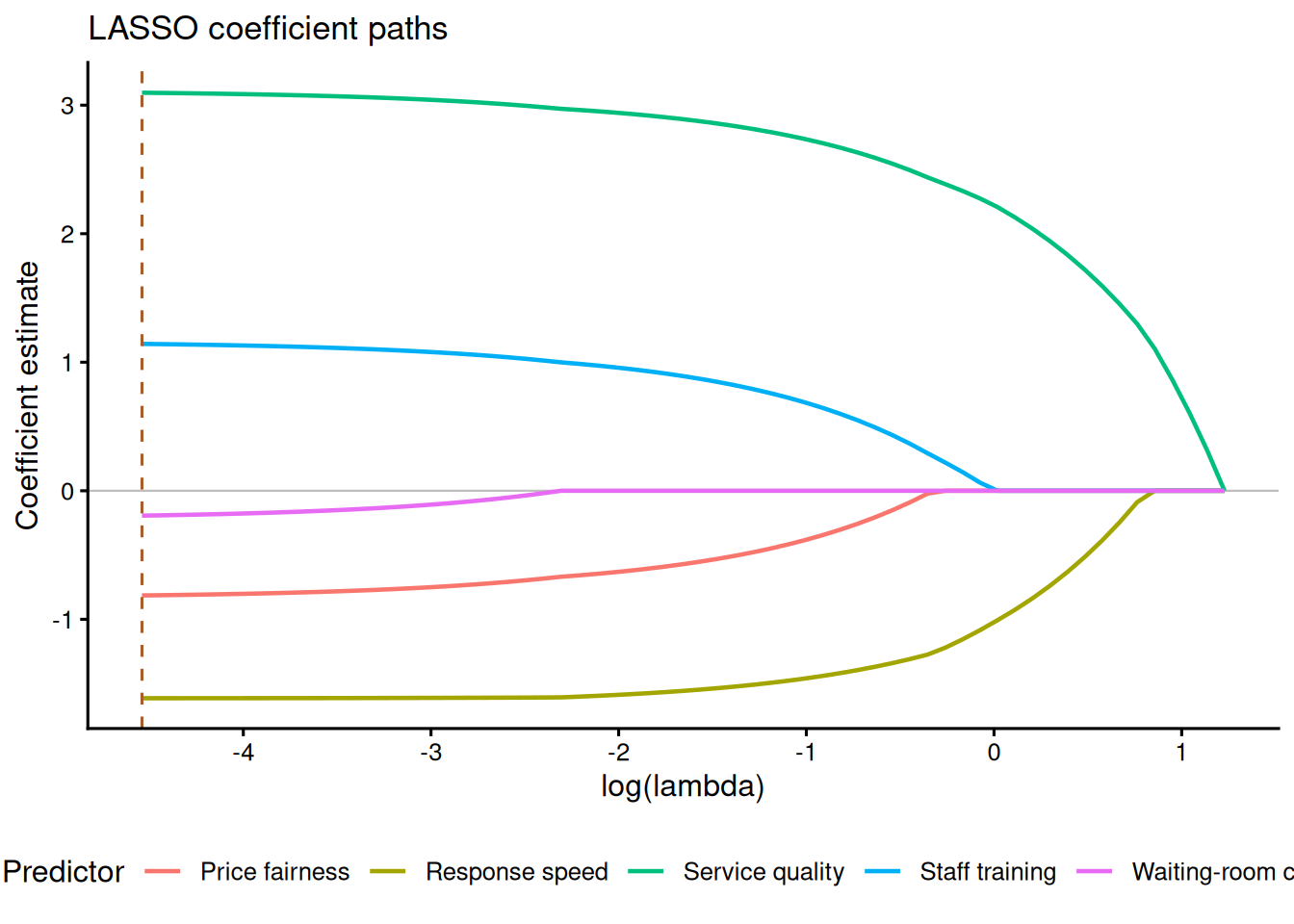
The main reporting point is the penalty rule, not just the final coefficients. If lambda.1se removes a predictor that lambda.min retains, describe that predictor as unstable rather than definitively absent. For explanatory work, LASSO is best used as a sensitivity analysis or screening tool before a simpler, pre-specified model is reported.
Bayesian Priors as Regularisation
Weakly informative priors are regularisation tools, not a way to force a preferred conclusion. A prior such as Normal(0, 2.5) on a logistic-regression coefficient implies that odds ratios between exp(-5) = 0.007 and exp(5) = 148 are plausible a priori while still regularising extreme estimates. Stronger priors such as Normal(0, 0.5) exert more shrinkage and should be justified by substantive knowledge or prior evidence (Gelman, Simpson, and Betancourt 2017).
Table 13.6 illustrates prior sensitivity for the wait-time slope in the customer-satisfaction example using a normal approximation to the likelihood. The table is not a replacement for full Bayesian computation, but it shows the main principle: when the prior is tight, the posterior moves toward zero. When the prior is weak, the posterior resembles the data-driven estimate.
Table 13.6
Prior-sensitivity illustration for a Bayesian regression slope
| Prior on wait-time slope | Posterior mean | Posterior SD | 95% credible interval |
|---|---|---|---|
| Normal(0, 0.5) | -0.17 | 0.27 | -0.69 to 0.36 |
| Normal(0, 1) | -0.21 | 0.30 | -0.81 to 0.38 |
| Normal(0, 2.5) | -0.23 | 0.32 | -0.85 to 0.39 |
| Normal(0, 10) | -0.24 | 0.32 | -0.86 to 0.39 |
Note. The approximation uses the ordinary least-squares wait-time slope and standard error as a normal likelihood. Full Bayesian analyses should still check convergence diagnostics, such as R-hat < 1.01 and effective sample size > 400, and should inspect posterior predictive fit.
For a full Bayesian fit, use an MCMC package and report diagnostics. The following code is intentionally not evaluated in the book render because brms requires a working Stan toolchain, but it is the minimal workflow expected in a manuscript: specify priors, sample, check R-hat and effective sample size, and inspect posterior predictive fit. Before running it locally, verify the Stan toolchain with cmdstanr::check_cmdstan_toolchain() if using CmdStan, or confirm the installed rstan version with rstan::stan_version() before fitting a small test model.
Bayesian regression reports posterior intervals rather than frequentist confidence intervals. A 95% credible interval describes the range containing 95% of posterior probability given the model, data, and priors. That statement is conditional on the prior choice, so small-sample Bayesian reports should include the priors, convergence diagnostics, posterior predictive checks, and at least one plausible prior-sensitivity analysis. For leave-one-out cross-validation or WAIC in Bayesian models, use them as approximate predictive checks, not as automatic proof that one small-sample model is correct (Vehtari, Gelman, and Gabry 2017).
Reporting Regularised Models
A regularised model report should make the stabilising assumption visible. State the outcome, sample size, event count where relevant, candidate predictors, standardisation, penalty or prior, tuning method and sensitivity checks. Do not report a penalised coefficient as if it were an ordinary unpenalised estimate.
For Firth logistic regression, report the sparse event table, the separation warning or diagnostic that motivated the method, coefficient scale, odds ratios if used, confidence intervals and software. For ridge and LASSO, report whether predictors were standardised, the value of lambda, how lambda was chosen, and whether conclusions change under lambda.min versus lambda.1se or under a simpler unpenalised model. For Bayesian models, report priors, seed, chains, iterations, R-hat, effective sample size, posterior intervals and posterior predictive checks.
A concise reporting sentence could read: “Because the ordinary logistic model produced fitted probabilities close to 0 and 1, we estimated a Firth-penalised logistic regression. The model included planning score and prior experience, reported coefficients on the log-odds scale with confidence intervals, and was interpreted as a stabilised sensitivity analysis rather than as precise evidence from a large sample.” That level of detail is enough for readers to see both the method and the limitation.
Key Takeaways
Penalised and Bayesian regression methods are valuable in small samples because they make unstable estimates finite and reduce overfitting. Firth logistic regression is especially useful for sparse binary outcomes and separation. Ridge regression shrinks correlated or noisy linear-model coefficients. LASSO can screen candidate predictors by setting unstable coefficients to zero. Bayesian priors regularise estimates and express assumptions directly. The reporting obligation is the same in all cases: show the data structure, state the penalty or prior, check sensitivity, and avoid treating regularised estimates as more precise than the sample supports.
Self-Assessment Quiz
Question 1. What does separation mean in logistic regression?
Explanation.
Separation occurs when the outcome can be nearly or perfectly predicted from the covariates. Standard logistic maximum likelihood can then produce extremely large or infinite coefficients.
Question 2. Why is Firth logistic regression useful with sparse binary outcomes?
Explanation.
Firth’s method uses a penalised likelihood that reduces small-sample bias and avoids infinite estimates. Event counts and uncertainty still need to be reported.
Question 3. What does ridge regression do to coefficients?
Explanation.
Ridge regression adds a squared-coefficient penalty. Larger penalties pull estimates toward zero and can reduce overfitting.
Question 4. In a small-sample Bayesian regression, why should prior sensitivity be reported?
Explanation.
When the data are thin, different plausible priors can lead to noticeably different posterior estimates. Reporting sensitivity shows how much the conclusion depends on modelling assumptions.
Question 5. Which statement is the safest interpretation of a regularised estimate?
Explanation.
Regularisation stabilises estimates by adding assumptions. Those assumptions, along with intervals and diagnostics, must be reported.