```{r}
#| include: false
suppressPackageStartupMessages(library(tidyverse))
suppressPackageStartupMessages(library(knitr))
suppressPackageStartupMessages(library(htmltools))
source(normalizePath(file.path(dirname(knitr::current_input(dir = TRUE)), "..", "R", "chapter_helpers.R"), mustWork = TRUE))
```
:::: {.content-visible when-format="html"}
```{webr-r}
#| context: setup
#| include: false
#| echo: false
smallsamplelab_service_quality_data <- function() {
data.frame(
respondent_id = 1:36,
branch = c(
"East", "South", "North", "North", "South", "North", "North", "South", "South", "North", "North", "South",
"North", "South", "South", "South", "East", "North", "North", "East", "North", "North", "North", "South",
"East", "East", "East", "South", "East", "North", "East", "South", "South", "North", "North", "South"
),
q1_responsiveness = c(6, 3, 4, 7, 6, 6, 7, 4, 4, 4, 4, 5, 5, 7, 4, 2, 5, 5, 6, 4, 4, 5, 4, 3, 3, 6, 4, 5, 4, 5, 2, 7, 5, 3, 4, 4),
q2_professionalism = c(5, 2, 5, 6, 4, 6, 4, 4, 5, 5, 5, 5, 5, 7, 3, 2, 3, 5, 7, 3, 6, 5, 4, 2, 3, 7, 5, 7, 4, 4, 3, 6, 5, 5, 6, 6),
q3_clarity = c(6, 5, 5, 7, 5, 6, 5, 2, 4, 5, 4, 7, 7, 7, 4, 3, 6, 6, 6, 5, 3, 3, 5, 3, 6, 7, 3, 6, 5, 5, 4, 7, 6, 4, 6, 5)
)
}
quality_items <- smallsamplelab_service_quality_data()[, c("q1_responsiveness", "q2_professionalism", "q3_clarity")]
```
::::
# Chapter 5: Reliability and Measurement Quality for Short Scales
### Learning Objectives
By the end of this chapter, you will be able to explain why reliability estimates behave differently in short scales, distinguish alpha, omega, and split-half coefficients, compute the main internal-consistency diagnostics in R, and report measurement quality with appropriate confidence intervals and small-sample caveats.
### The Challenge of Short Scales
Many small-sample studies use brief measurement instruments (3–5 items) to reduce respondent burden. Short scales, however, pose challenges for reliability assessment. Classical reliability indices (Cronbach's alpha, split-half reliability) are attenuated when scales have few items. Moreover, small sample sizes yield imprecise reliability estimates with wide confidence intervals.
Despite these limitations, reliability assessment remains essential. Unreliable measures introduce noise, reducing statistical power and biasing effect estimates. Researchers should report reliability alongside validity evidence and interpret findings cautiously when reliability is low.
### Cronbach's Alpha
Cronbach's alpha estimates internal consistency by comparing item variances to total scale variance. It assumes that all items measure a single underlying construct and that item true scores contribute equally to the total score, usually described as tau-equivalence. A stricter parallel-items model also requires equal error variances, whereas a congeneric model allows items to have different loadings. Alpha increases with the number of items and the average inter-item correlation.
**Assumptions**: Items are at least approximately tau-equivalent. Errors are uncorrelated. Continuous or approximately continuous item responses.
**When to use**: Multi-item scales (3 or more items), desire for simple internal consistency estimate. Interpret cautiously for short scales and with small samples.
### Interpreting Alpha in Context
Traditional thresholds (e.g., α ≥ 0.70 for research, α ≥ 0.90 for high-stakes decisions) are **heuristic benchmarks, not universal rules** [@devellis2021]:
- **Exploratory research / pilot studies**: α = 0.60–0.70 acceptable
- **Established scales in research**: α = 0.70–0.90 expected
- **High-stakes decisions**: α > 0.90 required
- **Very short scales** (3 items): α = 0.50–0.65 may be acceptable only when items are conceptually narrow and homogeneous, corrected item-total correlations exceed about 0.30, and the estimate is reported with its confidence interval
The alpha coefficient alone is rarely sufficient for assessing measurement quality. More diagnostic in most small-sample settings are the item-total correlations, which show whether each item contributes meaningfully to the composite; the conceptual coherence of the item set; and the width of the confidence interval around alpha, which reveals how much precision the sample size actually supports.
With n = 36, an alpha of 0.65 has an approximate 95% CI of [0.45, 0.80] under normal-theory assumptions. This wide interval reflects substantial sampling uncertainty: the true population reliability could range from questionable to good. Always report confidence intervals alongside point estimates. The default CI from `psych::alpha()` is based on an asymptotic standard error, which can be optimistic with small `n` or non-normal data; when computationally feasible, bootstrap intervals (for example via `boot::boot`) provide a useful robustness check.
::: {.callout-warning}
## Common Misconception: "Alpha > 0.70 = Good Scale"
**Myth**: "If Cronbach's alpha is above 0.70, my scale is reliable and valid."
**Reality**: Alpha can be **artificially inflated** by redundant items or scale length. High alpha ≠ good measurement.
**Demonstration**:
```{r}
#| label: part-c-misconception-4
#| results: asis
library(psych)
# Create a scale with near-duplicate items (bad scale design!)
set.seed(2025)
n <- 30
base_score <- rnorm(n, 50, 10)
redundant_scale <- tibble(
item1 = base_score,
item2 = base_score + rnorm(n, 0, 2),
item3 = base_score + rnorm(n, 0, 2),
item4 = base_score + rnorm(n, 0, 2)
)
# Compute alpha
invisible(capture.output(
alpha_result <- suppressWarnings(alpha(redundant_scale))
))
redundant_demo_display <- alpha_result$item.stats %>%
as.data.frame() %>%
rownames_to_column("Item") %>%
transmute(
Item,
`Corrected item-total correlation` = round(r.cor, 2)
)
chapter5_measurement_table(
"5.1",
"Corrected item-total correlations for the redundant-item demonstration",
redundant_demo_display,
note = paste0(
"Cronbach's alpha = ",
formatC(alpha_result$total$raw_alpha, format = "f", digits = 2),
". The high value reflects redundancy rather than broad construct coverage."
),
align = c("l", "r")
)
```
**Problems with high-but-meaningless alpha:**
1. **Redundant items**: Asking the same question 10 times inflates alpha but doesn't improve measurement
2. **Alpha increases with # items**: 20 poor items can yield α = 0.90 (following the Spearman-Brown relationship)
3. **Ignores unidimensionality**: Alpha doesn't test whether items measure one construct or multiple
**What to check instead:** Ask whether all items contribute meaningfully to the scale through their item-total correlations, whether the mean inter-item correlation falls in a plausible range of about 0.15 to 0.50 [@briggs1986; @clark1995], whether the items appear to reflect one coherent factor rather than several unrelated ones, and whether the content still covers the construct broadly enough to be useful. Values below about 0.15 suggest that items do not cohere well, whereas values above about 0.50 often indicate redundancy.
**Lesson**: **Don't chase alpha > 0.90 by adding redundant items.** Better to have α = 0.75 with diverse, non-redundant items than α = 0.95 with near-duplicates.
:::
### Example: Cronbach's Alpha for a Short Scale
We assess the internal consistency of a 3-item service quality scale using the `service_quality.csv` data.
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-2"}
#### Rendered Output
```{r}
#| label: part-c-chunk-22-html
#| echo: false
#| results: asis
library(tidyverse)
library(psych)
# Load service quality data
service_data <- read_csv("data/service_quality.csv", show_col_types = FALSE)
# Select the three quality items
quality_items <- service_data %>%
select(q1_responsiveness, q2_professionalism, q3_clarity)
# Compute Cronbach's alpha
invisible(capture.output(
alpha_result <- suppressWarnings(alpha(quality_items))
))
# Extract key values
alpha_est <- as.numeric(alpha_result$total$raw_alpha)
alpha_se <- as.numeric(alpha_result$total$ase)
alpha_stat <- function(data, indices) {
boot_items <- data[indices, , drop = FALSE]
value <- suppressWarnings(psych::alpha(boot_items, warnings = FALSE)$total$raw_alpha)
ifelse(is.finite(value), value, NA_real_)
}
set.seed(2025)
alpha_boot <- boot::boot(quality_items, statistic = alpha_stat, R = 1000)
alpha_boot_ci <- stats::quantile(alpha_boot$t[, 1], probs = c(0.025, 0.975), na.rm = TRUE)
alpha_summary <- tibble(
Metric = c(
"Cronbach's alpha",
"Asymptotic standard error",
"Bootstrap 95% CI lower bound",
"Bootstrap 95% CI upper bound",
"Bootstrap resamples"
),
Value = c(
alpha_est,
alpha_se,
alpha_boot_ci[[1]],
alpha_boot_ci[[2]],
1000
)
)
chapter5_measurement_table(
"5.2",
"Internal consistency summary for the 3-item service quality scale",
alpha_summary,
note = "The confidence interval is a percentile bootstrap interval over participants. The asymptotic standard error from <code>psych::alpha()</code> is shown for reference but is not used as the primary interval in this small-sample example.",
align = c("l", "r"),
digits = 3
)
```
#### Cell Code
```{webr-r}
#| context: interactive
library(dplyr)
library(ggplot2)
library(tidyr)
library(tibble)
library(purrr)
library(readr)
library(psych)
# Load service quality data
service_data <- smallsamplelab_service_quality_data()
# Select the three quality items
quality_items <- service_data %>%
select(q1_responsiveness, q2_professionalism, q3_clarity)
# Compute Cronbach's alpha
alpha_result <- alpha(quality_items)
print(alpha_result)
# Extract key values
alpha_est <- as.numeric(alpha_result$total$raw_alpha)
alpha_se <- as.numeric(alpha_result$total$ase)
alpha_stat <- function(data, indices) {
boot_items <- data[indices, , drop = FALSE]
value <- suppressWarnings(psych::alpha(boot_items, warnings = FALSE)$total$raw_alpha)
ifelse(is.finite(value), value, NA_real_)
}
set.seed(2025)
alpha_boot <- boot::boot(quality_items, statistic = alpha_stat, R = 1000)
alpha_boot_ci <- stats::quantile(alpha_boot$t[, 1], probs = c(0.025, 0.975), na.rm = TRUE)
cat("Cronbach's alpha:", formatC(alpha_est, format = "f", digits = 3), "\n")
cat("Bootstrap 95% CI:",
formatC(alpha_boot_ci[[1]], format = "f", digits = 3), "to",
formatC(alpha_boot_ci[[2]], format = "f", digits = 3), "\n")
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-chunk-22
#| results: asis
library(tidyverse)
library(psych)
# Load service quality data
service_data <- read_csv("data/service_quality.csv", show_col_types = FALSE)
# Select the three quality items
quality_items <- service_data %>%
select(q1_responsiveness, q2_professionalism, q3_clarity)
# Compute Cronbach's alpha
invisible(capture.output(
alpha_result <- suppressWarnings(alpha(quality_items))
))
# Extract key values
alpha_est <- as.numeric(alpha_result$total$raw_alpha)
alpha_se <- as.numeric(alpha_result$total$ase)
alpha_stat <- function(data, indices) {
boot_items <- data[indices, , drop = FALSE]
value <- suppressWarnings(psych::alpha(boot_items, warnings = FALSE)$total$raw_alpha)
ifelse(is.finite(value), value, NA_real_)
}
set.seed(2025)
alpha_boot <- boot::boot(quality_items, statistic = alpha_stat, R = 1000)
alpha_boot_ci <- stats::quantile(alpha_boot$t[, 1], probs = c(0.025, 0.975), na.rm = TRUE)
alpha_summary <- tibble(
Metric = c(
"Cronbach's alpha",
"Asymptotic standard error",
"Bootstrap 95% CI lower bound",
"Bootstrap 95% CI upper bound",
"Bootstrap resamples"
),
Value = c(
alpha_est,
alpha_se,
alpha_boot_ci[[1]],
alpha_boot_ci[[2]],
1000
)
)
chapter5_measurement_table(
"5.2",
"Internal consistency summary for the 3-item service quality scale",
alpha_summary,
note = "The confidence interval is a percentile bootstrap interval over participants. The asymptotic standard error from psych::alpha() is shown for reference but is not used as the primary interval in this small-sample example.",
align = c("l", "r"),
digits = 3
)
```
::::
Interpretation: Alpha quantifies the proportion of variance in scale scores attributable to the true score under the working assumptions of the model. Higher alpha indicates stronger internal consistency, but the bootstrap interval shows how uncertain the estimate remains in a small sample. If alpha is below 0.70, consider whether items truly measure a single construct or whether the scale is too heterogeneous. The `psych` package also reports "alpha if item deleted", showing how alpha would change if each item were removed; this helps identify problematic items.
### Standard Error of Measurement (SEM)
The SEM quantifies measurement precision: how much individual scores vary because of measurement error. In applied reporting, the reliability value is usually an estimate such as $\hat{\alpha}$ rather than a known population parameter, so the SEM is also an estimate and should be interpreted with the same uncertainty caveat.
**Formula**: $\widehat{\text{SEM}} = \text{SD} \times \sqrt{(1 - \hat{\alpha})}$
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-3"}
#### Rendered Output
```{r}
#| label: part-c-sem-html
#| echo: false
#| results: asis
# Example: Test with SD = 10, estimated Cronbach's alpha = 0.75
scale_SD <- 10
alpha_hat <- 0.75
SEM <- scale_SD * sqrt(1 - alpha_hat)
# Confidence interval for individual scores
# 95% CI: observed score ± 1.96 × SEM
CI_width <- 1.96 * SEM
sem_summary <- tibble(
Metric = c(
"Scale SD",
"Estimated alpha (alpha-hat)",
"Estimated SEM",
"95% CI half-width"
),
Value = c(scale_SD, alpha_hat, SEM, CI_width)
)
chapter5_measurement_table(
"5.3",
"Standard error of measurement example for a 10-point test",
sem_summary,
align = c("l", "r"),
digits = 2
)
```
#### Cell Code
```{webr-r}
#| context: interactive
# Example: Test with SD = 10, estimated Cronbach's alpha = 0.75
scale_SD <- 10
alpha_hat <- 0.75
SEM <- scale_SD * sqrt(1 - alpha_hat)
cat("SEM =", round(SEM, 2), "points\n")
# Confidence interval for individual scores
# 95% CI: observed score ± 1.96 × SEM
CI_width <- 1.96 * SEM
cat("95% CI width: ±", round(CI_width, 1), "points\n")
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-sem
#| results: asis
# Example: Test with SD = 10, estimated Cronbach's alpha = 0.75
scale_SD <- 10
alpha_hat <- 0.75
SEM <- scale_SD * sqrt(1 - alpha_hat)
# Confidence interval for individual scores
# 95% CI: observed score ± 1.96 × SEM
CI_width <- 1.96 * SEM
sem_summary <- tibble(
Metric = c(
"Scale SD",
"Estimated alpha (alpha-hat)",
"Estimated SEM",
"95% CI half-width"
),
Value = c(scale_SD, alpha_hat, SEM, CI_width)
)
chapter5_measurement_table(
"5.3",
"Standard error of measurement example for a 10-point test",
sem_summary,
align = c("l", "r"),
digits = 2
)
```
::::
**Interpretation**: With $\widehat{\text{SEM}} = 5$ points, an individual's true score likely falls within about ±10 points of their observed score under the working reliability estimate. This helps judge whether observed changes are genuine or merely measurement error. In practice, the minimum detectable change is about $1.96 \times \widehat{\text{SEM}} \times \sqrt{2} \approx 14$ points, so smaller changes could plausibly reflect measurement error alone. Because $\hat{\alpha}$ is estimated from a small sample, this SEM should be reported as approximate; when individual-level decisions matter, use a confidence band for reliability, or a bootstrap sensitivity check, to show how much the SEM changes across plausible reliability values.
### McDonald's Omega
McDonald's omega ($\omega_t$) is an alternative to alpha that relaxes the tau-equivalence assumption [@mcdonald1999]. It is computed from a common-factor model and reflects the proportion of variance in scale scores due to common factors. In realistic congeneric settings, omega is often preferred over alpha because it accommodates unequal factor loadings across items [@trizano2016].
**When to use**: Multi-item scales with varying item-factor relationships, when tau-equivalence is questionable, or when reporting alongside alpha for robustness.
### Example: McDonald's Omega
We compute omega for the same 3-item service quality scale.
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-4"}
#### Rendered Output
```{r}
#| label: part-c-chunk-23-html
#| echo: false
#| results: asis
library(psych)
# Compute McDonald's omega
invisible(capture.output(
omega_result <- suppressWarnings(suppressMessages(omega(quality_items, nfactors = 1, plot = FALSE)))
))
invisible(capture.output(
alpha_for_omega <- suppressWarnings(alpha(quality_items))
))
omega_tot <- as.numeric(omega_result$omega.tot)
alpha_for_omega_est <- as.numeric(alpha_for_omega$total$raw_alpha)
omega_summary <- tibble(
Metric = c(
"McDonald's omega total",
"Cronbach's alpha",
"Difference (omega - alpha)"
),
Value = c(
omega_tot,
alpha_for_omega_est,
omega_tot - alpha_for_omega_est
)
)
chapter5_measurement_table(
"5.4",
"Omega summary for the 3-item service quality scale",
omega_summary,
note = "Omega and alpha are very similar here, which is what we expect for a tightly unidimensional toy example.",
align = c("l", "r"),
digits = 3
)
```
#### Cell Code
```{webr-r}
#| context: interactive
library(psych)
# Compute McDonald's omega
omega_result <- omega(quality_items, nfactors = 1, plot = FALSE)
print(omega_result)
omega_tot <- as.numeric(omega_result$omega.tot)
cat("McDonald's omega total:", formatC(omega_tot, format = "f", digits = 3), "\n")
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-chunk-23
#| results: asis
library(psych)
# Compute McDonald's omega
invisible(capture.output(
omega_result <- suppressWarnings(suppressMessages(omega(quality_items, nfactors = 1, plot = FALSE)))
))
invisible(capture.output(
alpha_for_omega <- suppressWarnings(alpha(quality_items))
))
omega_tot <- as.numeric(omega_result$omega.tot)
alpha_for_omega_est <- as.numeric(alpha_for_omega$total$raw_alpha)
omega_summary <- tibble(
Metric = c(
"McDonald's omega total",
"Cronbach's alpha",
"Difference (omega - alpha)"
),
Value = c(
omega_tot,
alpha_for_omega_est,
omega_tot - alpha_for_omega_est
)
)
chapter5_measurement_table(
"5.4",
"Omega summary for the 3-item service quality scale",
omega_summary,
note = "Omega and alpha are very similar here, which is what we expect for a tightly unidimensional toy example.",
align = c("l", "r"),
digits = 3
)
```
::::
Interpretation: The `omega()` function reports two related indices. $\omega_t$ (omega total) summarises the proportion of total score variance attributable to all common factors, whereas $\omega_h$ (omega hierarchical) isolates the variance attributable to a general factor after accounting for group factors. For brief, unidimensional scales, $\omega_t$ is usually the relevant quantity. $\omega_h$ is more informative when evaluating multidimensional instruments with a bifactor-like structure.
With a perfectly unidimensional three-item example, some elements of the printed `omega()` output can look extreme. Values such as `omega_h = 1` or `max/min = Inf` reflect a degenerate single-factor solution with no modeled specific-factor variance. In this setting, they are a consequence of the toy example rather than evidence that the computation failed.
### Split-Half Reliability
Split-half reliability divides a scale into two halves, computes the correlation between half-scale scores, and adjusts using the Spearman–Brown formula to estimate reliability of the full scale. The adjustment is $r_{SB} = \frac{2r_{half}}{1 + r_{half}}$, where $r_{half}$ is the correlation between the two halves. This matters because reliability increases with scale length. With small samples, split-half estimates are imprecise, and different item splits can yield noticeably different values.
**When to use**: Multi-item scales, desire for alternative reliability estimate, comparison with alpha or omega.
### Example: Split-Half Reliability
We compute split-half reliability for the service quality scale and report the Spearman-Brown adjusted estimate.
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-5"}
#### Rendered Output
```{r}
#| label: part-c-chunk-24-html
#| echo: false
#| results: asis
library(psych)
set.seed(2025)
# Split-half reliability
invisible(capture.output(
split_result <- splitHalf(quality_items, raw = TRUE)
))
split_summary <- tibble(
Metric = c(
"Spearman-Brown adjusted reliability",
"Minimum split-half reliability",
"Maximum split-half reliability",
"Median split-half reliability"
),
Value = c(
as.numeric(split_result$alpha),
as.numeric(split_result$minrb),
as.numeric(split_result$maxrb),
as.numeric(split_result$ci[["50%"]])
)
)
chapter5_measurement_table(
"5.5",
"Split-half reliability summary for the service quality scale",
split_summary,
note = paste0(
"Least favourable split: ",
paste(split_result$minAB$A, collapse = ", "),
" versus ",
paste(split_result$minAB$B, collapse = ", "),
"."
),
align = c("l", "r"),
digits = 3
)
```
#### Cell Code
```{webr-r}
#| context: interactive
library(psych)
set.seed(2025)
# Split-half reliability
split_result <- splitHalf(quality_items, raw = TRUE)
print(split_result)
split_alpha <- as.numeric(split_result$alpha)
cat("Split-half reliability (Spearman–Brown adjusted):",
formatC(split_alpha, format = "f", digits = 3), "\n")
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-chunk-24
#| results: asis
library(psych)
set.seed(2025)
# Split-half reliability
invisible(capture.output(
split_result <- splitHalf(quality_items, raw = TRUE)
))
split_summary <- tibble(
Metric = c(
"Spearman-Brown adjusted reliability",
"Minimum split-half reliability",
"Maximum split-half reliability",
"Median split-half reliability"
),
Value = c(
as.numeric(split_result$alpha),
as.numeric(split_result$minrb),
as.numeric(split_result$maxrb),
as.numeric(split_result$ci[["50%"]])
)
)
chapter5_measurement_table(
"5.5",
"Split-half reliability summary for the service quality scale",
split_summary,
note = paste0(
"Least favourable split: ",
paste(split_result$minAB$A, collapse = ", "),
" versus ",
paste(split_result$minAB$B, collapse = ", "),
"."
),
align = c("l", "r"),
digits = 3
)
```
::::
Interpretation: The split-half correlation measures consistency between the two halves. The Spearman–Brown adjustment estimates the reliability of the full scale. This method is less commonly used than alpha but provides a complementary perspective. Because different item splits can yield different results, it is best treated as a robustness check rather than a single definitive reliability estimate.
### Worst Split-Half Reliability (Practical Alternative to Revelle's Beta)
This chapter reports the minimum split-half reliability across all admissible partitions from `psych::splitHalf()` as a practical stress test. Earlier editions of this text referenced Revelle's β, a related lower-bound estimate that focuses on the weakest split-half consistency; current `psych` workflows fold that logic into `splitHalf()`, so a separate helper is unnecessary. Unlike omega, which is factor-model based, the worst-split value is a stress test of how fragile the item set becomes under the least favourable partition.
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-6"}
#### Rendered Output
```{r}
#| label: part-c-chunk-25-html
#| echo: false
#| results: asis
invisible(capture.output(
split_result <- splitHalf(quality_items, raw = TRUE)
))
worst_split_display <- tibble(
Metric = c(
"Least favourable split reliability",
"Most favourable split reliability",
"Least favourable split A",
"Least favourable split B"
),
Value = c(
formatC(as.numeric(split_result$minrb), format = "f", digits = 3),
formatC(as.numeric(split_result$maxrb), format = "f", digits = 3),
paste(split_result$minAB$A, collapse = ", "),
paste(split_result$minAB$B, collapse = ", ")
)
)
chapter5_measurement_table(
"5.6",
"Worst-case split-half reliability for the service quality scale",
worst_split_display,
note = paste0(
"This chapter reports the minimum split-half reliability from <code>psych::splitHalf()</code>. Earlier editions referenced Revelle's β, but current psych workflows integrate that lower-bound logic within <code>splitHalf()</code> (here using psych ",
as.character(packageVersion("psych")),
")."
),
align = c("l", "l")
)
```
#### Cell Code
```{webr-r}
#| context: interactive
# Practical alternative: use the minimum split-half reliability from splitHalf()
split_result <- splitHalf(quality_items, raw = TRUE)
tibble(
Metric = c(
"Least favourable split reliability",
"Most favourable split reliability",
"Least favourable split A",
"Least favourable split B"
),
Value = c(
formatC(as.numeric(split_result$minrb), format = "f", digits = 3),
formatC(as.numeric(split_result$maxrb), format = "f", digits = 3),
paste(split_result$minAB$A, collapse = ", "),
paste(split_result$minAB$B, collapse = ", ")
)
)
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-chunk-25
#| results: asis
invisible(capture.output(
split_result <- splitHalf(quality_items, raw = TRUE)
))
worst_split_display <- tibble(
Metric = c(
"Least favourable split reliability",
"Most favourable split reliability",
"Least favourable split A",
"Least favourable split B"
),
Value = c(
formatC(as.numeric(split_result$minrb), format = "f", digits = 3),
formatC(as.numeric(split_result$maxrb), format = "f", digits = 3),
paste(split_result$minAB$A, collapse = ", "),
paste(split_result$minAB$B, collapse = ", ")
)
)
chapter5_measurement_table(
"5.6",
"Worst-case split-half reliability for the service quality scale",
worst_split_display,
note = paste0(
"This chapter reports the minimum split-half reliability from psych::splitHalf(). Earlier editions referenced Revelle's beta, but current psych workflows integrate that lower-bound logic within splitHalf() (here using psych ",
as.character(packageVersion("psych")),
")."
),
align = c("l", "l")
)
```
::::
Interpretation: The minimum split-half value is typically lower than the Spearman-Brown adjusted estimate because it focuses on the weakest admissible partition. Large gaps between the overall split-half estimate and the minimum split suggest that some item partitions are fragile, meaning the scale could behave inconsistently across subsets of items. With very small samples, these stress-test values can fluctuate; report them alongside alpha and omega and acknowledge the additional uncertainty.
### Polychoric Correlations for Ordinal Items
Likert-scale items (e.g., 1–7 ratings) are ordinal, not continuous. Pearson correlations and alpha computed on ordinal data may underestimate reliability. Polychoric correlations estimate the correlation between underlying continuous latent variables, assuming ordinal responses arise from categorising continuous variables.
When items are ordinal and have few response options, polychoric correlations and ordinal alpha may be more accurate. However, stable estimation often requires roughly n = 50–100, depending on the number of response categories and the observed distributions [@olsson1979]. With smaller samples, polychoric solutions may be unstable or fail to converge; in those cases, report Pearson-based alpha and note that ordinal methods were considered but were too uncertain for strong interpretation.
**When to use**: Ordinal items with few response categories, ideally with samples closer to n ≥ 50–100 when feasible, and when there is a clear need for theoretically appropriate latent-response correlations.
### Example: Polychoric Correlations (Conceptual)
We compute polychoric correlations for the service quality items. With n = 36, this example falls below the preferred range for stable polychoric estimation, so the result should be treated as illustrative rather than definitive.
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-7"}
#### Rendered Output
```{r}
#| label: part-c-chunk-26-html
#| echo: false
#| results: asis
library(psych)
# Polychoric correlation matrix with error handling
# Falls back to Pearson correlations if sample is too small
poly_result <- tryCatch(
polychoric(quality_items),
error = function(e) {
message("Polychoric estimation failed (sample too small). Using Pearson correlations.")
return(list(rho = cor(quality_items)))
}
)
# Compute alpha based on polychoric correlations
alpha_poly <- alpha(poly_result$rho)
alpha_poly_est <- as.numeric(alpha_poly$total$raw_alpha)
poly_display <- round(poly_result$rho, 3) %>%
as.data.frame() %>%
rownames_to_column("Item")
chapter5_measurement_table(
"5.7",
"Polychoric correlation matrix for the service quality items",
poly_display,
note = paste0(
"Alpha based on the polychoric correlation matrix = ",
formatC(alpha_poly_est, format = "f", digits = 3),
"."
),
align = c("l", "r", "r", "r"),
digits = 3
)
```
#### Cell Code
```{webr-r}
#| context: interactive
library(psych)
# Polychoric correlation matrix with error handling
# Falls back to Pearson correlations if sample is too small
poly_result <- tryCatch(
polychoric(quality_items),
error = function(e) {
message("Polychoric estimation failed (sample too small). Using Pearson correlations.")
return(list(rho = cor(quality_items)))
}
)
print(poly_result)
# Compute alpha based on polychoric correlations
alpha_poly <- alpha(poly_result$rho)
alpha_poly_est <- as.numeric(alpha_poly$total$raw_alpha)
cat("Alpha based on polychoric correlations:",
formatC(alpha_poly_est, format = "f", digits = 3), "\n")
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-chunk-26
#| results: asis
library(psych)
# Polychoric correlation matrix with error handling
# Falls back to Pearson correlations if sample is too small
poly_result <- tryCatch(
polychoric(quality_items),
error = function(e) {
message("Polychoric estimation failed (sample too small). Using Pearson correlations.")
return(list(rho = cor(quality_items)))
}
)
# Compute alpha based on polychoric correlations
alpha_poly <- alpha(poly_result$rho)
alpha_poly_est <- as.numeric(alpha_poly$total$raw_alpha)
poly_display <- round(poly_result$rho, 3) %>%
as.data.frame() %>%
rownames_to_column("Item")
chapter5_measurement_table(
"5.7",
"Polychoric correlation matrix for the service quality items",
poly_display,
note = paste0(
"Alpha based on the polychoric correlation matrix = ",
formatC(alpha_poly_est, format = "f", digits = 3),
"."
),
align = c("l", "r", "r", "r"),
digits = 3
)
```
::::
Interpretation: Polychoric correlations are typically higher than Pearson correlations for ordinal data, so alpha computed from the polychoric matrix may also be higher. However, with small samples these estimates can be unstable or fail to converge. If polychoric and Pearson results are similar, the method choice has little practical impact. If they differ substantially, report both and note that the ordinal estimate is more assumption-sensitive in small samples.
### Reporting Reliability with Small Samples
When reporting reliability for small samples and short scales:
- Report Cronbach's alpha with confidence intervals.
- Consider reporting McDonald's omega as a robustness check.
- Acknowledge limitations (short scale, small sample, wide CIs).
- Provide item-level descriptive statistics (means, SDs, inter-item correlations).
- Discuss implications for interpretation (e.g., "The modest alpha suggests caution in interpreting scale scores; findings should be replicated with longer instruments").
### Lab Practical 5.1: Refining a Workplace Resilience Scale
**Context**: An organizational psychologist developed a 6-item Workplace Resilience Scale (WRS) to measure employees' ability to cope with job stress. After piloting the scale with 22 employees, the researcher wants to evaluate internal consistency and decide whether to drop any items to improve reliability. This walkthrough demonstrates item analysis, alpha calculation, and item-deletion decisions.
**Learning Goals**:
- Compute Cronbach's alpha for a multi-item scale
- Examine item-total correlations to identify weak items
- Assess the impact of dropping items on reliability
- Make evidence-based decisions about scale refinement
- Understand context-dependent alpha thresholds
**Step 1: Load and Explore the Data**
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-8"}
#### Rendered Output
```{r}
#| label: part-c-lab-6-1-html
#| echo: false
#| results: asis
library(tidyverse)
library(psych)
# Simulated WRS data: 22 employees, 6 items (1-5 Likert scale)
set.seed(2025)
wrs_data <- tibble(
WRS1 = c(4, 5, 3, 4, 5, 4, 3, 5, 4, 3, 4, 5, 3, 4, 4, 5, 3, 4, 5, 4, 3, 4),
WRS2 = c(3, 4, 3, 3, 4, 3, 2, 4, 3, 3, 4, 4, 3, 3, 4, 4, 3, 3, 4, 3, 2, 3),
WRS3 = c(5, 5, 4, 5, 5, 4, 4, 5, 5, 4, 5, 5, 4, 5, 5, 5, 4, 5, 5, 4, 4, 5),
WRS4 = c(2, 1, 3, 2, 1, 3, 4, 1, 2, 3, 2, 1, 3, 2, 1, 1, 3, 2, 1, 3, 4, 2), # Weak item
WRS5 = c(4, 4, 3, 4, 4, 3, 3, 4, 4, 3, 4, 4, 3, 4, 4, 4, 3, 4, 4, 3, 3, 4),
WRS6 = c(3, 4, 3, 3, 4, 3, 2, 4, 3, 3, 4, 4, 3, 3, 4, 4, 3, 3, 4, 3, 2, 3)
)
# Descriptive statistics
wrs_descriptives <- wrs_data %>%
summarise(across(everything(), list(mean = mean, sd = sd))) %>%
pivot_longer(everything(), names_to = c("Item", ".value"), names_sep = "_") %>%
rename(Mean = mean, SD = sd)
chapter5_measurement_table(
"5.8",
"Item descriptive statistics for the Workplace Resilience Scale pilot",
wrs_descriptives,
align = c("l", "r", "r"),
digits = 2
)
```
#### Cell Code
```{webr-r}
#| context: interactive
library(dplyr)
library(ggplot2)
library(tidyr)
library(tibble)
library(purrr)
library(readr)
library(psych)
# Simulated WRS data: 22 employees, 6 items (1-5 Likert scale)
set.seed(2025)
wrs_data <- tibble(
WRS1 = c(4, 5, 3, 4, 5, 4, 3, 5, 4, 3, 4, 5, 3, 4, 4, 5, 3, 4, 5, 4, 3, 4),
WRS2 = c(3, 4, 3, 3, 4, 3, 2, 4, 3, 3, 4, 4, 3, 3, 4, 4, 3, 3, 4, 3, 2, 3),
WRS3 = c(5, 5, 4, 5, 5, 4, 4, 5, 5, 4, 5, 5, 4, 5, 5, 5, 4, 5, 5, 4, 4, 5),
WRS4 = c(2, 1, 3, 2, 1, 3, 4, 1, 2, 3, 2, 1, 3, 2, 1, 1, 3, 2, 1, 3, 4, 2), # Weak item
WRS5 = c(4, 4, 3, 4, 4, 3, 3, 4, 4, 3, 4, 4, 3, 4, 4, 4, 3, 4, 4, 3, 3, 4),
WRS6 = c(3, 4, 3, 3, 4, 3, 2, 4, 3, 3, 4, 4, 3, 3, 4, 4, 3, 3, 4, 3, 2, 3)
)
# Descriptive statistics
wrs_data %>%
summarise(across(everything(), list(mean = mean, sd = sd))) %>%
pivot_longer(everything(), names_to = c("Item", ".value"), names_sep = "_")
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-lab-6-1
#| results: asis
library(tidyverse)
library(psych)
# Simulated WRS data: 22 employees, 6 items (1-5 Likert scale)
set.seed(2025)
wrs_data <- tibble(
WRS1 = c(4, 5, 3, 4, 5, 4, 3, 5, 4, 3, 4, 5, 3, 4, 4, 5, 3, 4, 5, 4, 3, 4),
WRS2 = c(3, 4, 3, 3, 4, 3, 2, 4, 3, 3, 4, 4, 3, 3, 4, 4, 3, 3, 4, 3, 2, 3),
WRS3 = c(5, 5, 4, 5, 5, 4, 4, 5, 5, 4, 5, 5, 4, 5, 5, 5, 4, 5, 5, 4, 4, 5),
WRS4 = c(2, 1, 3, 2, 1, 3, 4, 1, 2, 3, 2, 1, 3, 2, 1, 1, 3, 2, 1, 3, 4, 2), # Weak item
WRS5 = c(4, 4, 3, 4, 4, 3, 3, 4, 4, 3, 4, 4, 3, 4, 4, 4, 3, 4, 4, 3, 3, 4),
WRS6 = c(3, 4, 3, 3, 4, 3, 2, 4, 3, 3, 4, 4, 3, 3, 4, 4, 3, 3, 4, 3, 2, 3)
)
# Descriptive statistics
wrs_descriptives <- wrs_data %>%
summarise(across(everything(), list(mean = mean, sd = sd))) %>%
pivot_longer(everything(), names_to = c("Item", ".value"), names_sep = "_") %>%
rename(Mean = mean, SD = sd)
chapter5_measurement_table(
"5.8",
"Item descriptive statistics for the Workplace Resilience Scale pilot",
wrs_descriptives,
align = c("l", "r", "r"),
digits = 2
)
```
::::
**Checkpoint**: Items have similar means (3–4) and SDs (0.5–1.0), except WRS4 shows a lower mean and higher SD. That pattern suggests it may not align with the rest of the scale and could be weakly keyed or reverse-worded.
**Step 2: Compute Cronbach's Alpha (Full Scale)**
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-9"}
#### Rendered Output
```{r}
#| label: part-c-lab-6-2-html
#| echo: false
#| results: asis
# Compute alpha for all 6 items
invisible(capture.output(
alpha_full <- suppressWarnings(alpha(wrs_data))
))
wrs_alpha_summary <- tibble(
Metric = c(
"Raw alpha",
"Standardized alpha",
"Average inter-item correlation",
"Signal-to-noise ratio"
),
Value = c(
as.numeric(alpha_full$total$raw_alpha),
as.numeric(alpha_full$total$std.alpha),
as.numeric(alpha_full$total$average_r),
as.numeric(alpha_full$total[["S/N"]])
)
)
chapter5_measurement_table(
"5.9",
"Full-scale reliability summary for the 6-item WRS pilot",
wrs_alpha_summary,
note = "The negative WRS4 item pulls the full-scale estimate down sharply and should be inspected before any deletion decision is made.",
align = c("l", "r"),
digits = 3
)
```
#### Cell Code
```{webr-r}
#| context: interactive
# Compute alpha for all 6 items
alpha_full <- alpha(wrs_data)
print(alpha_full)
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-lab-6-2
#| results: asis
# Compute alpha for all 6 items
invisible(capture.output(
alpha_full <- suppressWarnings(alpha(wrs_data))
))
wrs_alpha_summary <- tibble(
Metric = c(
"Raw alpha",
"Standardized alpha",
"Average inter-item correlation",
"Signal-to-noise ratio"
),
Value = c(
as.numeric(alpha_full$total$raw_alpha),
as.numeric(alpha_full$total$std.alpha),
as.numeric(alpha_full$total$average_r),
as.numeric(alpha_full$total[["S/N"]])
)
)
chapter5_measurement_table(
"5.9",
"Full-scale reliability summary for the 6-item WRS pilot",
wrs_alpha_summary,
note = "The negative WRS4 item pulls the full-scale estimate down sharply and should be inspected before any deletion decision is made.",
align = c("l", "r"),
digits = 3
)
```
::::
**Checkpoint**: The raw alpha is very low here because one item is working in the opposite direction from the rest of the scale, not because every item is equally weak. The standardised alpha asks the same question after putting items on a common variance scale, the mean inter-item correlation shows how tightly the items move together, and the signal-to-noise ratio summarises how much reliable variance remains once error is considered. The key practical question is whether the "reliability if an item is dropped" table shows a sharp improvement for a specific item, because that pattern usually points to reverse coding or conceptual mismatch rather than to a uniformly poor scale.
**Step 3: Examine Item-Total Correlations**
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-10"}
#### Rendered Output
```{r}
#| label: part-c-lab-6-3-html
#| echo: false
#| results: asis
# Extract item-total correlations
item_stats <- alpha_full$item.stats
# Display key statistics
item_stats_display <- item_stats %>%
as.data.frame() %>%
rownames_to_column("Item") %>%
transmute(
Item,
`Corrected item-total correlation` = r.cor,
`Raw item-total correlation` = r.drop,
Mean = mean,
SD = sd
) %>%
arrange(`Corrected item-total correlation`)
chapter5_measurement_table(
"5.10",
"Item-total statistics for the 6-item WRS pilot",
item_stats_display,
align = c("l", "r", "r", "r", "r"),
digits = 3
)
```
#### Cell Code
```{webr-r}
#| context: interactive
# Extract item-total correlations
item_stats <- alpha_full$item.stats
# Display key statistics
item_stats %>%
select(r.cor, r.drop, mean, sd) %>%
arrange(r.cor)
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-lab-6-3
#| results: asis
# Extract item-total correlations
item_stats <- alpha_full$item.stats
# Display key statistics
item_stats_display <- item_stats %>%
as.data.frame() %>%
rownames_to_column("Item") %>%
transmute(
Item,
`Corrected item-total correlation` = r.cor,
`Raw item-total correlation` = r.drop,
Mean = mean,
SD = sd
) %>%
arrange(`Corrected item-total correlation`)
chapter5_measurement_table(
"5.10",
"Item-total statistics for the 6-item WRS pilot",
item_stats_display,
align = c("l", "r", "r", "r", "r"),
digits = 3
)
```
::::
**Checkpoint**: Look for:
- **r.cor**: Corrected item-total correlation (item vs. scale without that item). Values < 0.30 indicate weak contribution
- **r.drop**: Raw item-total correlation (item vs. full scale including that item)
Items with r.cor < 0.30 deserve close review. Here, WRS4 is negatively related to the rest of the scale, which points to either an unrecoded reverse-worded item or a construct mismatch rather than simple low reliability.
**Step 4: Assess "Alpha if Item Dropped"**
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-11"}
#### Rendered Output
```{r}
#| label: part-c-lab-6-4-html
#| echo: false
#| results: asis
# Extract alpha-if-deleted
alpha_if_dropped <- alpha_full$alpha.drop
# Display with item labels
alpha_if_dropped_display <- alpha_if_dropped %>%
as.data.frame() %>%
rownames_to_column("Item") %>%
transmute(
Item,
`Alpha if item dropped` = raw_alpha
) %>%
arrange(desc(`Alpha if item dropped`))
chapter5_measurement_table(
"5.11",
"Alpha if each WRS item were removed",
alpha_if_dropped_display,
align = c("l", "r"),
digits = 3
)
```
#### Cell Code
```{webr-r}
#| context: interactive
# Extract alpha-if-deleted
alpha_if_dropped <- alpha_full$alpha.drop
# Display with item labels
alpha_if_dropped %>%
select(raw_alpha) %>%
arrange(desc(raw_alpha))
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-lab-6-4
#| results: asis
# Extract alpha-if-deleted
alpha_if_dropped <- alpha_full$alpha.drop
# Display with item labels
alpha_if_dropped_display <- alpha_if_dropped %>%
as.data.frame() %>%
rownames_to_column("Item") %>%
transmute(
Item,
`Alpha if item dropped` = raw_alpha
) %>%
arrange(desc(`Alpha if item dropped`))
chapter5_measurement_table(
"5.11",
"Alpha if each WRS item were removed",
alpha_if_dropped_display,
align = c("l", "r"),
digits = 3
)
```
::::
**Checkpoint**: Dropping WRS4 produces a very large improvement in alpha, which confirms that it is destabilizing the scale. In practice, the next step is to inspect the item wording and scoring key before deciding whether to delete it or reverse-score it.
**Step 5: Recompute Alpha Without WRS4**
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-12"}
#### Rendered Output
```{r}
#| label: part-c-lab-6-5-html
#| echo: false
#| results: asis
# Drop WRS4 and recompute alpha
wrs_refined <- wrs_data %>% select(-WRS4)
invisible(capture.output(
alpha_refined <- suppressWarnings(alpha(wrs_refined))
))
alpha_comparison <- tibble(
Scale = c("Full 6-item scale", "Refined 5-item scale (WRS4 removed)"),
Items = c("6", "5"),
`Cronbach's alpha` = c(
formatC(alpha_full$total$raw_alpha, format = "f", digits = 3),
formatC(alpha_refined$total$raw_alpha, format = "f", digits = 3)
)
)
chapter5_measurement_table(
"5.12",
"Reliability before and after removing WRS4",
alpha_comparison,
note = paste0(
"Alpha increases by ",
formatC(alpha_refined$total$raw_alpha - alpha_full$total$raw_alpha, format = "f", digits = 3),
" after removing the misaligned item."
),
align = c("l", "r", "r")
)
```
#### Cell Code
```{webr-r}
#| context: interactive
# Drop WRS4 and recompute alpha
wrs_refined <- wrs_data %>% select(-WRS4)
alpha_refined <- alpha(wrs_refined)
print(alpha_refined)
# Compare full vs. refined alpha
cat("Full scale alpha:", round(alpha_full$total$raw_alpha, 3), "\n")
cat("Refined scale alpha (WRS4 dropped):", round(alpha_refined$total$raw_alpha, 3), "\n")
cat("Improvement:", round(alpha_refined$total$raw_alpha - alpha_full$total$raw_alpha, 3), "\n")
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: part-c-lab-6-5
#| results: asis
# Drop WRS4 and recompute alpha
wrs_refined <- wrs_data %>% select(-WRS4)
invisible(capture.output(
alpha_refined <- suppressWarnings(alpha(wrs_refined))
))
alpha_comparison <- tibble(
Scale = c("Full 6-item scale", "Refined 5-item scale (WRS4 removed)"),
Items = c("6", "5"),
`Cronbach's alpha` = c(
formatC(alpha_full$total$raw_alpha, format = "f", digits = 3),
formatC(alpha_refined$total$raw_alpha, format = "f", digits = 3)
)
)
chapter5_measurement_table(
"5.12",
"Reliability before and after removing WRS4",
alpha_comparison,
note = paste0(
"Alpha increases by ",
formatC(alpha_refined$total$raw_alpha - alpha_full$total$raw_alpha, format = "f", digits = 3),
" after removing the misaligned item."
),
align = c("l", "r", "r")
)
```
::::
**Checkpoint**: The refined 5-item scale has much higher alpha and all remaining items show strong positive item-total correlations. That is a more internally consistent measure, but the jump is so large that it also suggests the remaining items may be quite redundant.
**Step 6: Interpret in Context**
Follow these guidelines:
- **Research/exploratory scales**: α ≥ 0.60–0.70 acceptable
- **Established scales in research**: α ≥ 0.70–0.80 preferred
- **High-stakes decisions (clinical, personnel)**: α ≥ 0.80–0.90 required
- **Short scales (3–5 items)**: Expect alpha to run about 0.05–0.10 lower than for longer scales with similar item quality
**Decision**: WRS4 requires immediate inspection because:
1. It has a negative corrected item-total correlation
2. Dropping it increases alpha dramatically
3. The remaining 5-item scale shows high internal consistency
If WRS4 was intentionally reverse-worded, recode it first and then rerun the reliability analysis before making a final deletion decision.
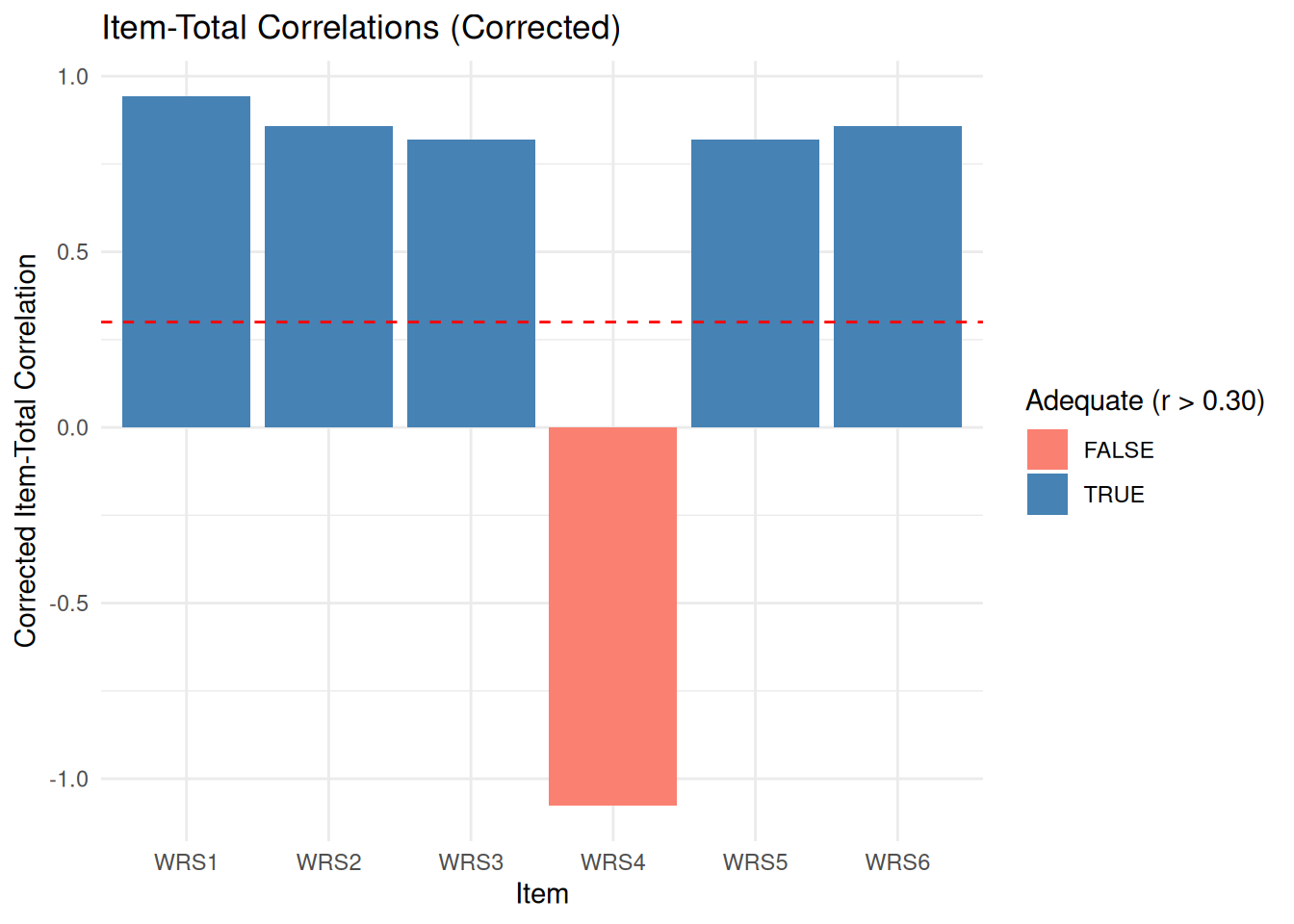
**Step 7: Visualise Item Performance**
Figure 5.1 shows the corrected item-total correlations for the pilot Workplace Resilience Scale. The dashed reference line marks the usual review threshold of about 0.30, making it easy to see why WRS4 demands immediate follow-up.
:::: {.content-visible when-format="html"}
::::: {.panel-tabset group="part-c-analysis-methods-chapter-6-reliability-and-measurement-quality-for-short-scales-cell-13"}
#### Rendered Output
```{r}
#| label: qfig-ch5-item-performance-web
#| echo: false
#| fig-align: center
#| fig-cap: "Figure 5.1: Corrected item-total correlations for the pilot Workplace Resilience Scale."
#| alt: "Corrected item-total correlations for the pilot Workplace Resilience Scale."
# Create item performance plot
item_performance <- item_stats %>%
rownames_to_column("Item") %>%
select(Item, r.cor, mean, sd)
ggplot(item_performance, aes(x = Item, y = r.cor, fill = r.cor > 0.30)) +
geom_col() +
geom_hline(yintercept = 0.30, linetype = "dashed", color = "red") +
labs(
title = "Item-Total Correlations (Corrected)",
x = "Item",
y = "Corrected Item-Total Correlation",
fill = "Adequate (r > 0.30)"
) +
theme_minimal() +
scale_fill_manual(values = c("TRUE" = "steelblue", "FALSE" = "salmon"))
```
#### Cell Code
```{webr-r}
#| context: interactive
# Create item performance plot
item_performance <- item_stats %>%
rownames_to_column("Item") %>%
select(Item, r.cor, mean, sd)
ggplot(item_performance, aes(x = Item, y = r.cor, fill = r.cor > 0.30)) +
geom_col() +
geom_hline(yintercept = 0.30, linetype = "dashed", color = "red") +
labs(
title = "Item-Total Correlations (Corrected)",
x = "Item",
y = "Corrected Item-Total Correlation",
fill = "Adequate (r > 0.30)"
) +
theme_minimal() +
scale_fill_manual(values = c("TRUE" = "steelblue", "FALSE" = "salmon"))
```
:::::
::::
:::: {.content-visible unless-format="html"}
```{r}
#| label: qfig-ch5-item-performance
#| fig-align: center
#| fig-cap: "Figure 5.1: Corrected item-total correlations for the pilot Workplace Resilience Scale."
#| alt: "Corrected item-total correlations for the pilot Workplace Resilience Scale."
# Create item performance plot
item_performance <- item_stats %>%
rownames_to_column("Item") %>%
select(Item, r.cor, mean, sd)
ggplot(item_performance, aes(x = Item, y = r.cor, fill = r.cor > 0.30)) +
geom_col() +
geom_hline(yintercept = 0.30, linetype = "dashed", color = "red") +
labs(
title = "Item-Total Correlations (Corrected)",
x = "Item",
y = "Corrected Item-Total Correlation",
fill = "Adequate (r > 0.30)"
) +
theme_minimal() +
scale_fill_manual(values = c("TRUE" = "steelblue", "FALSE" = "salmon"))
```
::::
**Checkpoint**: The plot clearly shows that WRS4 falls well below the acceptable range and in fact moves in the opposite direction from the other items.
**Step 8: Report the Results**
> "The 6-item Workplace Resilience Scale was piloted with 22 employees. Initial reliability analysis suggested severe internal-consistency problems (raw alpha = 0.10), driven by WRS4, which showed a negative corrected item-total correlation (r = -0.98). Removing that item increased alpha to 0.94, indicating that the remaining five items were highly consistent. Before deleting WRS4 permanently, the researcher should verify whether it was intentionally reverse-worded and therefore requires reverse scoring rather than omission. Future validation should use a larger sample and include test-retest reliability."
**Discussion Questions**:
1. Why is item-total correlation more informative than item mean or SD?
Item-total correlation shows how well an item captures the same construct as the rest of the scale. An item can have a reasonable mean and standard deviation yet still dilute reliability if it does not move with the other items.
2. What if two items both have r.cor < 0.30?
Review them one at a time rather than dropping both immediately. Recompute alpha after each change and check whether either item is reverse-worded, badly phrased, or intentionally measuring a distinct facet that the scale still needs.
3. Should you always maximise alpha by dropping items?
No. Dropping items can improve internal consistency while also narrowing content coverage too far. In many applied settings, an alpha around 0.70 with broader construct coverage is preferable to a higher alpha achieved by keeping only a few overly redundant items.
4. How does sample size affect these decisions?
Small samples make item-total correlations and alpha estimates unstable, so item decisions should remain tentative when n is very limited. Strong deletion decisions are best revisited once a larger validation sample is available.
**Extension**: Reverse-score WRS4 if its wording is intentionally opposite in direction, then compare the recoded solution with the deletion approach. You can also compute split-half reliability or omega to assess whether the remaining items behave as a coherent short scale.
### Key Takeaways
Cronbach's alpha, McDonald's omega, and split-half estimates each provide useful but incomplete views of internal consistency. Short scales naturally produce lower coefficients than longer scales, and small samples make all of those estimates more uncertain, which is why confidence intervals and item-level diagnostics matter as much as the point estimate itself. Reliability should therefore be reported transparently, interpreted alongside content coverage and dimensionality, and treated as one part of measurement quality rather than a single threshold to clear.
---
### Self-Assessment Quiz
Test your understanding of reliability and measurement quality from Chapter 5.
```{r}
#| echo: false
#| results: asis
source(normalizePath(file.path(dirname(knitr::current_input(dir = TRUE)), "..", "R", "quiz_helpers.R"), mustWork = TRUE))
smallsamplelab_render_quiz(list(
list(
prompt = "Cronbach's alpha measures:",
options = c("Whether data are normally distributed", "Internal consistency—how closely related a set of items are", "Test-retest reliability", "Inter-rater agreement"),
answer = 2L,
explanation = "Cronbach's alpha quantifies internal consistency by comparing item variances to total scale variance. It indicates whether items measure a common construct. The chapter states: \"Cronbach's alpha estimates internal consistency by comparing item variances to total scale variance.\""
),
list(
prompt = "What is the main limitation of Cronbach's alpha?",
options = c("It requires n>1,000", "It assumes tau-equivalence (equal factor loadings across items)", "It cannot be calculated for short scales", "It is always too high"),
answer = 2L,
explanation = "Alpha assumes all items contribute equally to the construct (tau-equivalence). When items have varying loadings, alpha may underestimate reliability. McDonald's omega relaxes this assumption. The chapter explicitly notes alpha \"assumes that all items measure a single underlying construct with equal factor loadings (tau-equivalent model).\""
),
list(
prompt = "A 3-item scale has α=0.55 with n=25. Is this acceptable?",
options = c("No—alpha must always exceed 0.70", "Possibly—short scales naturally have lower alpha; consider context, item-total correlations, and CI", "Yes—always acceptable", "No—the scale must be discarded"),
answer = 2L,
explanation = "Alpha depends on scale length; 3-item scales often yield α=0.50-0.65 even when internally consistent. Check: (1) item-total correlations (all >0.30?), (2) alpha's 95% CI (precision), (3) conceptual coherence. For exploratory work, α=0.55 may be acceptable. This reflects the chapter's nuanced guidance about context-dependent thresholds rather than rigid cutoffs."
),
list(
prompt = "McDonald's omega is preferred over alpha when:",
options = c("Items have equal factor loadings", "Items have varying factor loadings (not tau-equivalent)", "Sample size exceeds 500", "Data are categorical"),
answer = 2L,
explanation = "Omega (ω_total) allows items to have different factor loadings, providing a more accurate reliability estimate when tau-equivalence does not hold. The chapter states: \"McDonald's omega (ωₜ) is an alternative to alpha that relaxes the tau-equivalence assumption.\""
),
list(
prompt = "Item-total correlation measures:",
options = c("How well an item correlates with the total scale score (excluding that item)", "Test-retest stability", "The mean of all items", "Sample size adequacy"),
answer = 1L,
explanation = "Corrected item-total correlation indicates how strongly each item relates to the overall scale. Values <0.30 suggest the item measures something different or is poorly worded. The lab practical emphasizes examining item-total correlations as a diagnostic tool."
),
list(
prompt = "What does \"alpha if item deleted\" show?",
options = c("The p-value for each item", "How alpha would change if a specific item were removed", "The mean of each item", "Whether items are normally distributed"),
answer = 2L,
explanation = "If alpha increases substantially when an item is removed, that item is weakening internal consistency (low correlation with others or measuring a different construct). Consider revising or removing it. This is a standard feature of reliability analysis output used to identify problematic items."
),
list(
prompt = "Polychoric correlations are used when:",
options = c("Items are continuous and normally distributed", "Items are ordinal (e.g., Likert scales) and you want to estimate correlations between underlying continuous latent variables", "Sample size exceeds 1,000", "Data have no missing values"),
answer = 2L,
explanation = "Polychoric correlations assume ordinal responses arise from categorizing underlying continuous variables. They often yield higher estimates than Pearson correlations for Likert data, but stable estimation often needs samples closer to n = 50–100. The chapter discusses them as theoretically appropriate for ordinal items, while also warning that very small samples can make them unstable."
),
list(
prompt = "A scale has α=0.72 with n=36. The 95% CI is [0.52, 0.86]. What does this tell us?",
options = c("Reliability is excellent", "Reliability is moderate, but precision is limited (wide CI) due to small sample", "The scale is unreliable", "More items must be added"),
answer = 2L,
explanation = "The point estimate (0.72) suggests acceptable reliability, but the wide CI reflects substantial uncertainty with n=36. The true population alpha could be as low as 0.52 (questionable) or as high as 0.86 (good). The chapter emphasizes that \"small samples produce imprecise reliability estimates with wide confidence intervals.\""
),
list(
prompt = "Split-half reliability involves:",
options = c("Testing participants twice", "Dividing items into two halves, computing correlation, and applying Spearman-Brown correction", "Removing half the sample", "Using different raters"),
answer = 2L,
explanation = "Split-half reliability divides a scale into two halves (e.g., odd vs even items), correlates the half-scores, then adjusts using the Spearman-Brown formula to estimate full-scale reliability. This is a classic alternative method for assessing reliability mentioned in the learning objectives."
),
list(
prompt = "A scale shows α=−0.15. What is the most likely cause?",
options = c("Perfect reliability", "Reverse-coded items not properly recoded, or items measuring different constructs", "Sample size too large", "Normal distribution"),
answer = 2L,
explanation = "Negative alpha indicates that the average inter-item covariance is negative. This usually means reverse-coded items were not recoded, but it can also occur when the scale combines items tapping opposing constructs. Check the inter-item correlation matrix for negative values before interpreting the scale."
)
))
```